Free AI OCR Playground
Experience a Leading Document Understanding Technology. Powered by DeepSeek OCR and PaddleOCR
Drag, Drop, and Understand
Upload an image or PDF and experience the power of PaddleOCR-VL technology.
Ready to See the Magic?
Upload your own file, or select one of our examples to get started.
💡 Quick Tip: Choose the right engine!
- Select PaddleOCR for speed and most common documents.
- Switch to DeepSeek OCR for maximum accuracy on complex layouts.
⚡️ Performance Tips
- Smaller files process faster (keep resolution reasonable).
- Try different task types (e.g., Markdown) to see the results change!
- Free PDFs: First page only. Multi-page support is a coming Pro feature.Join the waitlist!
From Image to Insight: A Guide to Our OCR Toolkit
Learn how to convert any image, PDF, or document into structured, usable data in just a few clicks.
Upload Image
Drag & drop, paste, or provide a URL to your image. Supports all common image formats.
Select Model Size
Choose from Tiny to Gundam. We recommend Gundam for best overall performance, or select based on your speed/accuracy needs.
Choose Task Type
Select the appropriate task: document conversion, general OCR, figure parsing, or custom tasks with your own prompt.
Process & Export
Click Process and wait for results. View rendered markdown, raw text, or visualization with bounding boxes. Copy with one click.
Model Size Guide
Task Type Guide
What's Next for DeepSeek-OCR?
We're just getting started. Here’s a look at what we’re building next to make document understanding even more powerful.
In Progress
Actively being built and tested now.
Pro-Tier Priority Queue
Paid users get priority processing for near-instant results, every time.
Expanded Model Library
Access other specialized OCR models for different languages and use-cases.
Batch Processing
Upload and process hundreds of documents in a single go, right from the web interface.
Planned
Next on our list to design and build.
Developer API
Integrate the full power of DeepSeek-OCR directly into your applications and workflows.
Advanced PDF Support
Process multi-page PDFs while preserving layouts, tables, and document structure.
Exploring
Big ideas we're researching for the future.
Team Collaboration
Share projects, manage documents, and collaborate with your entire team.
Cloud Integrations
Connect directly to Google Drive, Dropbox, and more to process files automatically.
Advanced Data Parsing
Use AI to automatically extract specific structured data, like invoice totals or contact info.
Want access to these features first?
Join the Pro WaitlistOne Tool, Multiple Abilities
DeepSeek-OCR is more than just a text extractor. It's a versatile vision model capable of performing a wide range of document and image intelligence tasks.
Free OCR
Extracts raw, unformatted text from any image or document page. Perfect for quick digitization and content extraction.


Convert to Markdown
Preserves the document's structure, including headings, lists, and tables, by converting it into clean, readable Markdown.


Parse Figure
Goes beyond text to extract structured data from charts and graphs, turning visual information into usable data tables.

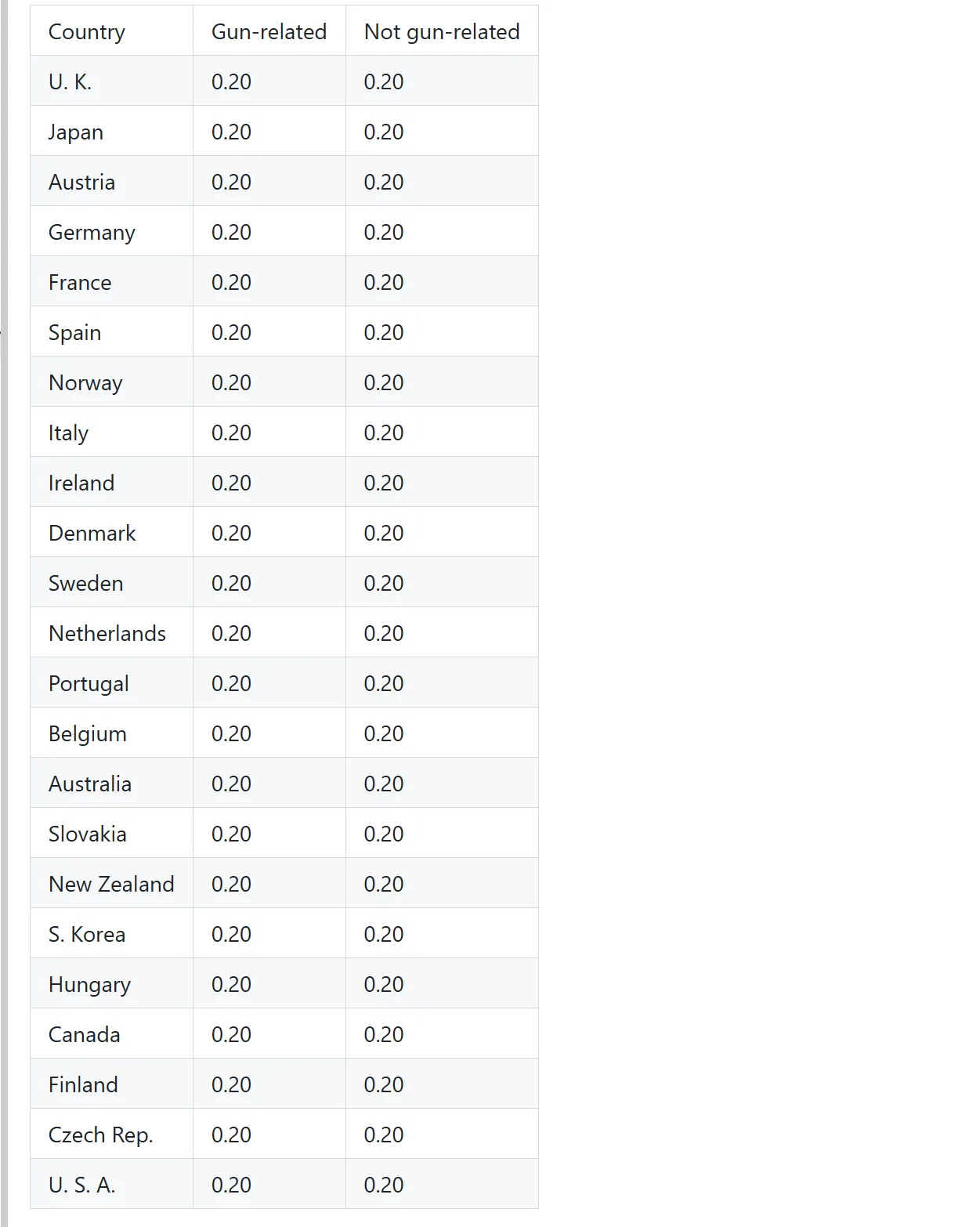
Locate Object (Grounding)
Finds specific text or elements within an image based on your prompt, providing precise bounding box coordinates.

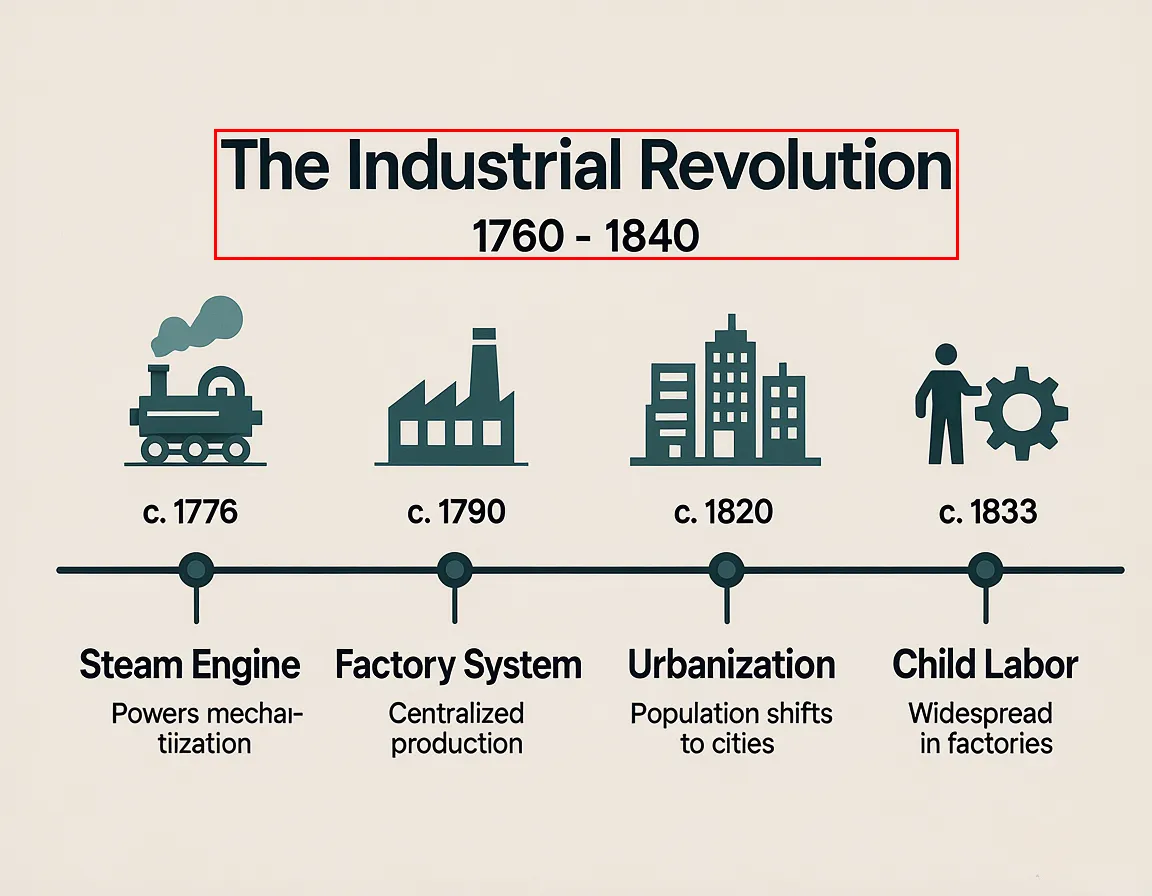
Detailed Image Description
Functions as a powerful Vision-Language Model, providing rich, detailed captions and descriptions for any image.


From Research to Enterprise: Real-World Applications
DeepSeek-OCR unlocks new possibilities across industries by making sophisticated document analysis accessible and scalable.
Accelerating Academic & Historical Research
Digitize entire archives in record time.
Researchers can now convert vast libraries of scanned papers, historical texts, and manuscripts into machine-readable text with incredible speed. The model's ability to handle diverse layouts and languages makes it an indispensable tool for data mining in the humanities and sciences.


Automating Financial Data Extraction
Turn reports into structured data.
Effortlessly extract tables, charts, and key figures from dense financial reports, invoices, and bank statements. The high accuracy and layout-aware parsing reduce manual data entry, minimize errors, and accelerate financial workflows and analysis.

Powering Next-Gen AI with Quality Data
The ultimate data source for LLMs.
Generate vast, high-quality datasets for training Large Language Models (LLMs) and Vision-Language Models (VLMs). DeepSeek-OCR's efficiency makes it economically viable to process millions of documents, creating diverse and rich training corpora.

Creating Efficient Digital Libraries
Archive, search, and manage documents.
Transform physical documents into a lightweight, searchable digital archive. The optical compression ensures that storage requirements are minimized while the high-quality text extraction makes every document instantly discoverable.

A Breakthrough in Efficiency and Accuracy
DeepSeek-OCR isn't just another text recognition tool. It's a fundamental rethinking of how machines process visual information, built to be both powerful and lightweight.
Contexts Optical Compression
The core innovation. We represent high-resolution documents with a fraction of the vision tokens, dramatically reducing computational costs and increasing processing speed.
State-of-the-Art Accuracy
Achieve up to 97% OCR precision on complex benchmarks. DeepSeek-OCR surpasses leading models while using significantly fewer resources.
Versatile Document Parsing
Go beyond plain text. Intelligently extract data from complex layouts, including academic papers, financial charts, chemical formulas, and geometric figures.
Built for Massive Scale
Engineered for real-world deployment, capable of processing over 200,000 pages per day on a single GPU, making it ideal for large-scale data annotation and LLM training.
Global Language Recognition
Trained on a vast dataset covering nearly 100 languages, allowing for accurate text extraction from international documents without changing models.
Low-Memory Architecture
The novel DeepEncoder design processes high-resolution images while maintaining low activation memory, enabling deployment on less powerful hardware and reducing operational costs.
Frequently Asked Questions
What is DeepSeek-OCR?▼
DeepSeek-OCR is a new vision-language model that specializes in recognizing and extracting text and data from documents using an innovative technique called 'Contexts Optical Compression'.
What makes 'Contexts Optical Compression' different?▼
Instead of converting every detail of an image into a large number of tokens, it intelligently compresses the visual information. This means it can represent a full, complex page with up to 10x fewer data points than traditional models, making it incredibly fast and efficient.
Is DeepSeek-OCR free to use?▼
Yes, the model is open-source and the live demo on this site is free to use. For commercial or large-scale use, you can access the model weights and code from the official GitHub repository.
Is there an official API available?▼
Currently, there is no official hosted API. However, the project is open-source, allowing you to deploy and host your own instance. We recommend following the GitHub project for future announcements about a public API.
What file types can I analyze?▼
The underlying model can process a wide range of image formats (PNG, JPEG, WebP) and is particularly effective on pages from PDF documents. The live demo supports direct image uploads and pastes.
How does this compare to Tesseract or other OCR libraries?▼
DeepSeek-OCR is an end-to-end deep learning model that excels at understanding complex layouts, like tables and charts, which traditional OCR libraries often struggle with. Its primary advantage is superior efficiency and accuracy on dense, structured documents.
What languages does the model support?▼
The model was trained on a massive dataset covering nearly 100 languages, making it highly effective for multilingual document analysis.
Can it understand document structure, not just text?▼
Absolutely. This is a key strength. It can parse charts into structured data, understand tables, and recognize layouts, converting them into clean formats like Markdown.
Explore More OCR Tools
From formula recognition to invoice extraction, find the OCR solution that fits your needs

AI OCR
AI poweres text extraction from any image or PDF

Formula OCR
Instantly convert math equations from images to editable LaTeX.

Handwriting OCR
Handwritten notes to editable text

Image OCR
Instantly convert any image to text

Invoice OCR
Extract invoice data automatically

OCR Scanner
Scan documents, images, and photos to editable text

Passport OCR
Free Extract Passport Details

PDF OCR
Convert PDFs and scanned documents to text

Receipt OCR
Extract data from receipts automatically
Experience the Difference Yourself
Reading about it is one thing, but seeing it in action is another. Scroll back up to the playground and analyze your own document to witness the speed and accuracy of DeepSeek-OCR firsthand.
Be the First to Know
We are developing an enhanced suite of tools built on DeepSeek-OCR, including API access and advanced features. Join the waitlist to get notified when we launch.