Бесплатная песочница OCR
Испытайте передовую технологию понимания документов. На базе DeepSeek OCR и PaddleOCR
Перетащите и поймите
Загрузите изображение или PDF и испытайте мощь технологии PaddleOCR-VL.
Готовы увидеть магию?
Загрузите свой файл или выберите один из наших примеров, чтобы начать.
💡 Быстрый совет: Выберите правильный движок!
- Выберите PaddleOCR для скорости и большинства обычных документов.
- Переключитесь на DeepSeek OCR для максимальной точности на сложных макетах.
⚡️ Советы по производительности
- Файлы меньшего размера обрабатываются быстрее (сохраняйте разумное разрешение).
- Попробуйте разные типы задач (например, Markdown), чтобы увидеть, как меняются результаты!
- Бесплатные PDF: Только первая страница. Поддержка многостраничности — в будущей Pro версии.В лист ожидания!
От изображения к инсайту: Руководство по нашему набору инструментов OCR
Узнайте, как конвертировать любое изображение, PDF или документ в структурированные, пригодные для использования данные всего за несколько кликов.
Загрузить изображение
Перетащите, вставьте или укажите URL вашего изображения. Поддерживает все распространенные форматы изображений.
Выбрать размер модели
Выберите от Tiny до Gundam. Мы рекомендуем Gundam для лучшей общей производительности или выберите в зависимости от ваших потребностей в скорости/точности.
Выбрать тип задачи
Выберите подходящую задачу: конвертация документа, общий OCR, разбор фигур или пользовательские задачи с вашим собственным промптом.
Обработать и экспортировать
Нажмите Обработать и ждите результатов. Просматривайте отрендеренный markdown, исходный текст или визуализацию с ограничивающими рамками. Копируйте одним кликом.
Руководство по размеру модели
Руководство по типу задачи
Что дальше для DeepSeek-OCR?
Мы только начинаем. Вот взгляд на то, что мы строим дальше, чтобы сделать понимание документов еще более мощным.
В процессе
Активно разрабатывается и тестируется сейчас.
Приоритетная очередь Pro-уровня
Платные пользователи получают приоритетную обработку для почти мгновенных результатов каждый раз.
Расширенная библиотека моделей
Доступ к другим специализированным моделям OCR для разных языков и сценариев использования.
Пакетная обработка
Загружайте и обрабатывайте сотни документов за один раз, прямо из веб-интерфейса.
Запланировано
Следующее в нашем списке для проектирования и разработки.
API для разработчиков
Интегрируйте полную мощь DeepSeek-OCR прямо в ваши приложения и рабочие процессы.
Продвинутая поддержка PDF
Обрабатывайте многостраничные PDF, сохраняя макеты, таблицы и структуру документа.
Исследуем
Большие идеи, которые мы исследуем для будущего.
Командное сотрудничество
Делитесь проектами, управляйте документами и сотрудничайте со всей командой.
Облачные интеграции
Подключайтесь напрямую к Google Drive, Dropbox и другим сервисам для автоматической обработки файлов.
Продвинутый парсинг данных
Используйте ИИ для автоматического извлечения конкретных структурированных данных, таких как итоги счетов или контактная информация.
Хотите получить доступ к этим функциям первыми?
В лист ожидания ProОдин инструмент, множество возможностей
DeepSeek-OCR — это больше, чем просто извлечение текста. Это универсальная модель зрения, способная выполнять широкий спектр задач по анализу документов и изображений.
Бесплатный OCR
Извлекает необработанный, неформатированный текст из любого изображения или страницы документа. Идеально для быстрой оцифровки и извлечения контента.


Конвертировать в Markdown
Сохраняет структуру документа, включая заголовки, списки и таблицы, преобразуя его в чистый, читаемый Markdown.


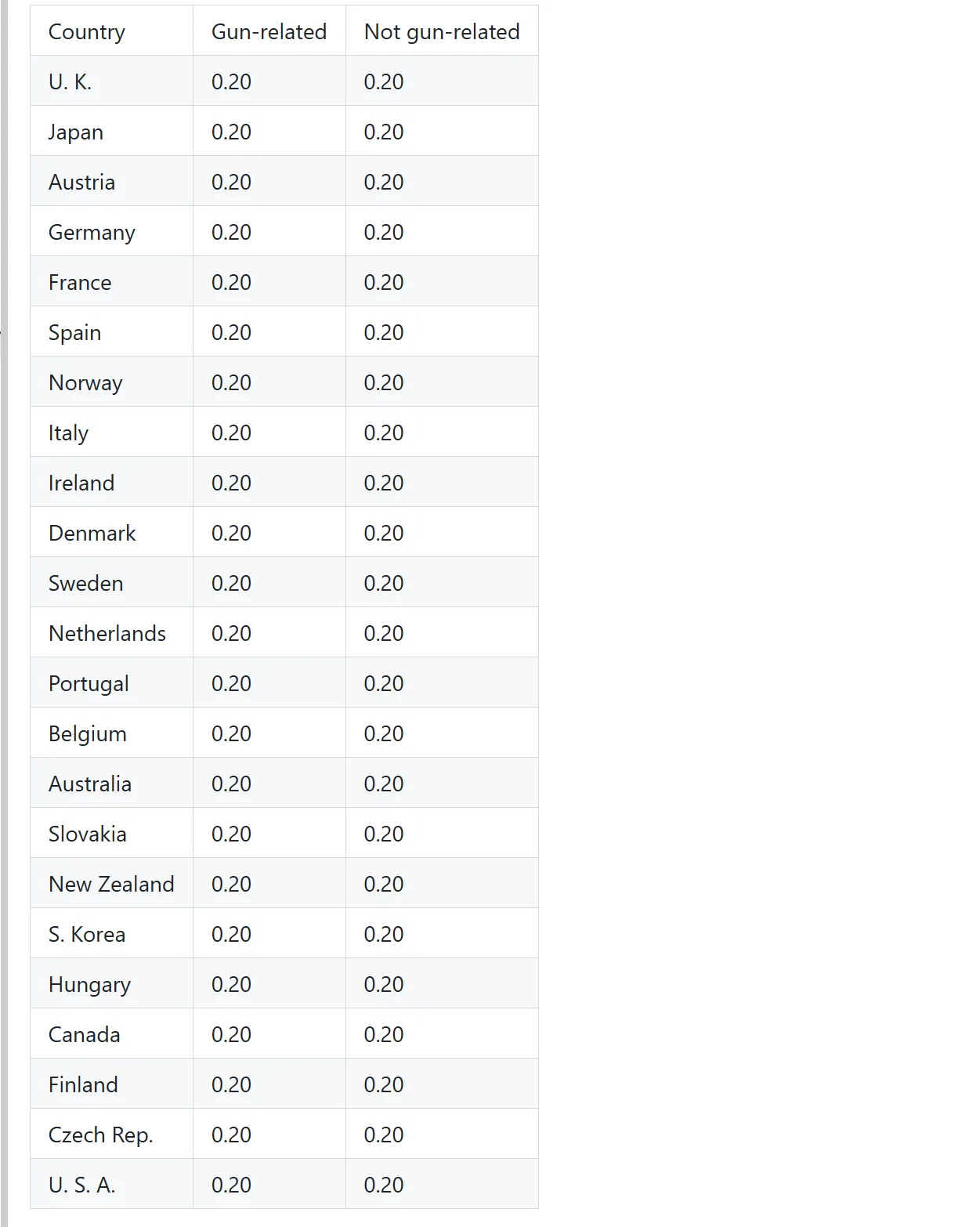
Разбор фигур
Выходит за рамки текста, извлекая структурированные данные из диаграмм и графиков, превращая визуальную информацию в пригодные для использования таблицы данных.

Найти объект (Grounding)
Находит конкретный текст или элементы внутри изображения на основе вашего промпта, предоставляя точные координаты ограничивающих рамок.

Детальное описание изображения
Работает как мощная модель Vision-Language, предоставляя богатые, подробные подписи и описания для любого изображения.


От исследований до бизнеса: Реальные применения
DeepSeek-OCR открывает новые возможности в различных отраслях, делая сложный анализ документов доступным и масштабируемым.
Ускорение академических и исторических исследований
Оцифровывайте целые архивы в рекордные сроки.
Исследователи теперь могут конвертировать огромные библиотеки отсканированных статей, исторических текстов и рукописей в машиночитаемый текст с невероятной скоростью. Способность модели обрабатывать разнообразные макеты и языки делает ее незаменимым инструментом для майнинга данных в гуманитарных и естественных науках.


Автоматизация извлечения финансовых данных
Превращайте отчеты в структурированные данные.
Легко извлекайте таблицы, графики и ключевые цифры из плотных финансовых отчетов, счетов и банковских выписок. Высокая точность и разбор с учетом макета сокращают ручной ввод данных, минимизируют ошибки и ускоряют финансовые рабочие процессы и анализ.

Питание ИИ следующего поколения качественными данными
Идеальный источник данных для LLM.
Генерируйте огромные, высококачественные наборы данных для обучения больших языковых моделей (LLM) и моделей зрение-язык (VLM). Эффективность DeepSeek-OCR делает экономически выгодной обработку миллионов документов, создавая разнообразные и богатые корпуса для обучения.

Создание эффективных цифровых библиотек
Архивируйте, ищите и управляйте документами.
Превращайте физические документы в легкий, доступный для поиска цифровой архив. Оптическое сжатие гарантирует минимизацию требований к хранению, а высококачественное извлечение текста делает каждый документ мгновенно доступным для поиска.

Прорыв в эффективности и точности
DeepSeek-OCR — это не просто еще один инструмент распознавания текста. Это фундаментальное переосмысление того, как машины обрабатывают визуальную информацию, созданное, чтобы быть мощным и легким.
Оптическое сжатие контекста
Ключевая инновация. Мы представляем документы высокого разрешения с помощью доли токенов зрения, значительно снижая вычислительные затраты и увеличивая скорость обработки.
Точность мирового уровня
Достигайте до 97% точности OCR на сложных бенчмарках. DeepSeek-OCR превосходит ведущие модели, используя значительно меньше ресурсов.
Универсальный разбор документов
Выходите за рамки простого текста. Интеллектуально извлекайте данные из сложных макетов, включая научные статьи, финансовые графики, химические формулы и геометрические фигуры.
Создан для масштабирования
Разработан для реального внедрения, способен обрабатывать более 200,000 страниц в день на одном GPU, что делает его идеальным для масштабной аннотации данных и обучения LLM.
Глобальное распознавание языков
Обучен на огромном наборе данных, охватывающем почти 100 языков, что позволяет точно извлекать текст из международных документов без смены моделей.
Архитектура с низким потреблением памяти
Новый дизайн DeepEncoder обрабатывает изображения высокого разрешения, сохраняя низкую память активации, что позволяет развертывание на менее мощном оборудовании и снижает операционные расходы.
Часто задаваемые вопросы
Что такое DeepSeek-OCR?▼
DeepSeek-OCR — это новая модель зрение-язык, которая специализируется на распознавании и извлечении текста и данных из документов с использованием инновационной техники под названием 'Оптическое сжатие контекста'.
В чем отличие 'Оптического сжатия контекста'?▼
Вместо преобразования каждой детали изображения в большое количество токенов, она интеллектуально сжимает визуальную информацию. Это означает, что она может представить полную, сложную страницу с использованием до 10 раз меньшего количества данных, чем традиционные модели, что делает ее невероятно быстрой и эффективной.
Бесплатен ли DeepSeek-OCR?▼
Да, модель имеет открытый исходный код, и живая демонстрация на этом сайте бесплатна для использования. Для коммерческого или масштабного использования вы можете получить доступ к весам модели и коду в официальном репозитории GitHub.
Есть ли официальный API?▼
В настоящее время официального хостинг-API нет. Однако проект имеет открытый исходный код, что позволяет вам развернуть и разместить собственный экземпляр. Мы рекомендуем следить за проектом на GitHub для будущих анонсов о публичном API.
Какие типы файлов я могу анализировать?▼
Базовая модель может обрабатывать широкий спектр форматов изображений (PNG, JPEG, WebP) и особенно эффективна на страницах из PDF документов. Живая демонстрация поддерживает прямую загрузку изображений и вставку.
Как это сравнивается с Tesseract или другими библиотеками OCR?▼
DeepSeek-OCR — это сквозная модель глубокого обучения, которая превосходит другие в понимании сложных макетов, таких как таблицы и диаграммы, с которыми традиционные библиотеки OCR часто испытывают трудности. Ее основное преимущество — превосходная эффективность и точность на плотных, структурированных документах.
Какие языки поддерживает модель?▼
Модель была обучена на огромном наборе данных, охватывающем почти 100 языков, что делает ее высокоэффективной для многоязычного анализа документов.
Может ли она понимать структуру документа, а не только текст?▼
Абсолютно. Это ключевая сильная сторона. Она может разбирать диаграммы в структурированные данные, понимать таблицы и распознавать макеты, преобразуя их в чистые форматы, такие как Markdown.
Изучите больше инструментов OCR
От распознавания формул до извлечения данных из счетов — найдите решение OCR, которое подходит именно вам

AI OCR
Извлечение текста из любого изображения или PDF с помощью ИИ

Распознавание формул
Мгновенное преобразование математических уравнений из изображений в редактируемый LaTeX.

Распознавание рукописного текста
Рукописные заметки в редактируемый текст

Распознавание изображений
Мгновенное извлечение текста из любого изображения

Распознавание счетов
Автоматическое извлечение данных из счетов

OCR Сканер
Сканирование документов, изображений и фото в редактируемый текст

Распознавание паспортов
Бесплатное извлечение данных паспорта

OCR для PDF
Конвертация сканированных PDF в доступные для поиска и редактирования документы

Распознавание чеко
Автоматическое извлечение данных из чеков
Почувствуйте разницу сами
Читать об этом — одно, а видеть в действии — другое. Прокрутите вверх к песочнице и проанализируйте свой документ, чтобы воочию убедиться в скорости и точности DeepSeek-OCR.
Узнайте первыми
Мы разрабатываем расширенный набор инструментов на базе DeepSeek-OCR, включая доступ к API и продвинутые функции. Присоединяйтесь к списку ожидания, чтобы получить уведомление о запуске.